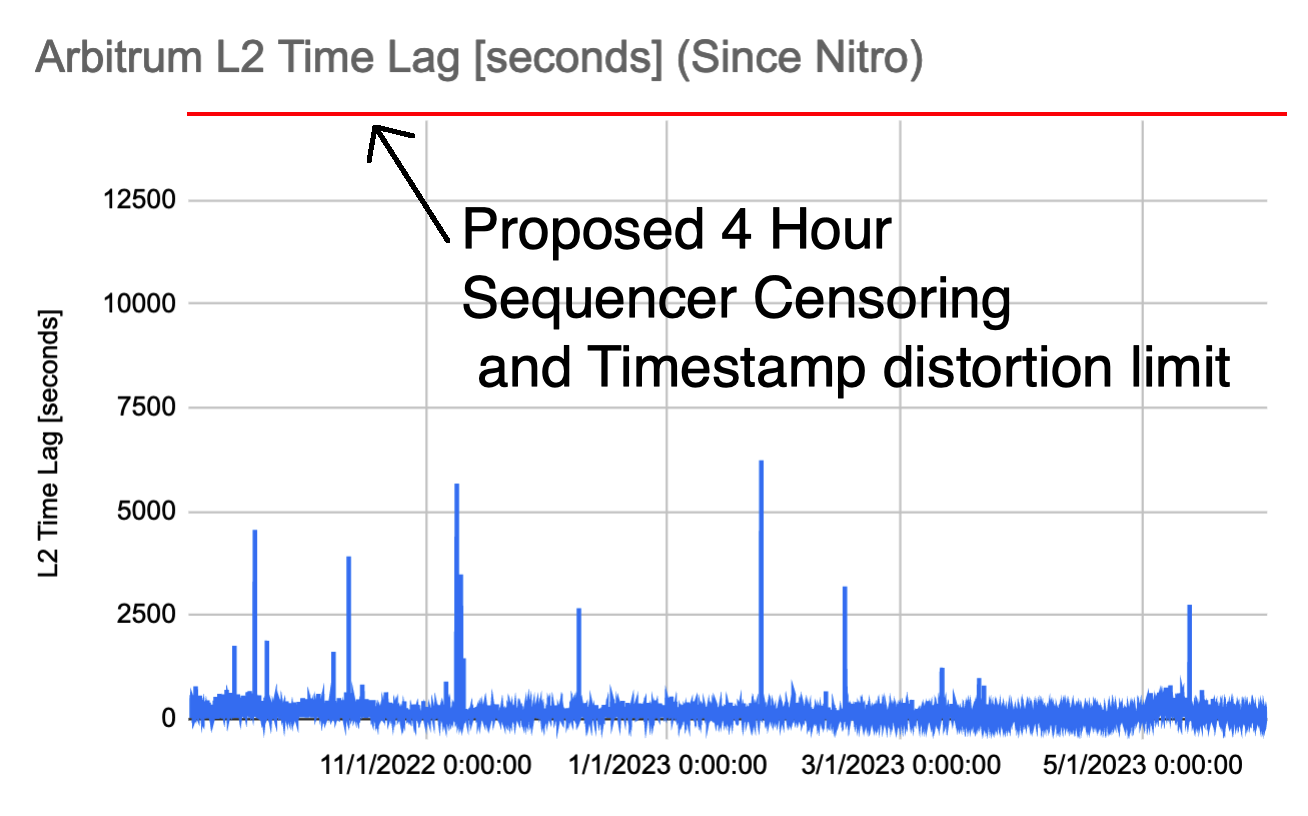
TLDR: If it’s necessary to lower the window, we think lowering it to 12 hours instead of 4 hours would eliminate a significant amount of risk.
The above discussion has already covered many important points on this topic, and this post mostly just attempts to lay out the various tradeoffs involved.
The core of the discussion is the force inclusion mechanism which allows any user to trigger the sequencing of delayed messages that were inserted into the delayed inbox sufficiently long before the current time. The mechanism doesn’t allow any change in ordering of those delayed messages, just to read further messages in order until a given message has been included.
This mechanism guarantees that even if the sequencer goes completely offline, users of the chain can still exit the system securely. It also provides a strong guard against censorship since it provides a mechanism where a user can permissionlessly force the inclusion of a transaction.
Note that when the sequencer is operating normally, shortening the 24 hour force inclusion window has no security benefit since the sequencer can’t backdate a transaction earlier than the most recently posted batch which tends to be less than a minute old.
There are three main categories of scenarios where the force inclusion mechanism could be triggered:
- The sequencer is completely down and hasn’t accepted transactions since the last batch was posted
- Batches are being posted regularly, but the sequencer is not reading messages from the delayed inbox
- The sequencer is accepting transactions, but unable to post batches
The main stated upside of this proposal is to provide a guarantee of transaction inclusion within a (shorter) bounded window on the DAO’s Arbitrum chains even with a byzantine sequencer. The argument is that users can achieve that guarantee by posting to the delayed inbox and forcing inclusion if necessary. Therefore the upper bound would be time to include transaction on ethereum + force inclusion window. There’s certainly a lot of value in providing a stronger guarantee of inclusion time. This proposal is for one specific way of achieving this, but I think a wider discussion of methods for achieving this would be valuable since the current proposal creates significant risks.
Any of the states that would lead to force inclusion being callable can be reached by either an honest sequencer with malfunctioning software or a malicious sequencer intentionally deviated from the expected behavior. We can generally ignore the malicious sequencer case in the following analysis since a malicious sequencer could disrupt of soft confirmation and create MEV opportunities without halting delayed message inclusion. Therefore the remaining analysis will focus on the honest, but malfunctioning sequencer case.
The severity of the consequences of the force inclusion mechanism being triggered differ depending on the scenario.
- In the first scenario, there’s no reorg at all from the force inclusion mechanism since no transactions have been confirmed by the sequencer that haven’t ended up onchain.
- In the second scenario, there may be a couple minutes of soft confirmed transactions reorged, but since batches are posted by the Arbitrum One sequencer quite often (every 30-60 seconds approximately), minimal transactions would be affected.
- The third scenario is where the force inclusion mechanism would have serious consequences. If the sequencer has still been offering soft confirmations for the length of the inclusion window, there would likely be a reorg of everything since the last batch was posted leading to large scale MEV extraction opportunities. Avoiding this scenario is a very high priority.
As an aside, one possible way to minimize the likelihood of the third scenario would be for the sequencer to stop accepting transactions if there was an issue posting batches onchain. However the advantage of the current strategy is that soft confirmation liveness can stay available even if onchain finality isn’t advancing. Batch poster downtime incidents would be much more severe under this alternate policy.
There are a number of tradeoffs and considerations when it comes to setting the length of time before a user can trigger the force inclusion mechanism. Generally speaking, the core issue with having a shorter period, is that it limits the amount of time available to respond to any issues.
The Offchain Labs Site Reliability Engineering team is of the opinion that reducing the force inclusion window to 4 hours unreasonably increases the risk of a potential reorg. Several factors contribute to this risk, which we will discuss below.
To better grasp the tradeoffs involved, we must examine the common failure cases of batch posting, which can be categorized into general infrastructure failures and software bugs requiring a codebase patch for resolution. Enhancing the batch poster’s reliability to meet the increased uptime guarantee would necessitate additional resources, including personnel and infrastructure, at an added cost. The primary concern arises when a software bug necessitates a code patch. An example response process for such an issue is as follows:
- Batch poster encounters an error - 00:00
- Automated alerting initiates when batches are detected as not being posted - 00:30
- SRE member responds - 00:30-00:45
- SRE member diagnoses the problem - 00:45-01:00
- Software issue identified, and Nitro developer paged - 01:00-01:15
- Nitro developer locates the bug and patches it - 01:15-03:00
- Image build on branch commences - 03:00-03:30
- SRE team deploys new image - 03:30-03:45
- If not fixed, sequencer messages face reorgs once the maximum downtime limit is reached - 04:00
While this process can be effective in some cases, it allows a very short window for the software issue to be diagnosed, patched, and tested before deployment to avoid reaching the force inclusion window. If the patch fails to resolve the problem in production, there would be minimal time available for a secondary patch attempt. Moreover, ensuring redundancy in the on-call schedule for the Nitro team would require increased coverage, as the current setup is only in place for the SRE team.
Considering the increased costs associated with this proposal and the heightened risk of sequencer message reorgs, we believe a 4-hour window is not feasible if we want to ensure that there will be no reorgs with the current staffing. In order to have a decent confidence level that deep reorgs could be prevented with high confidence, significantly more staff would have to be added both on the SRE team as well as Nitro team to be able to meet the timeline with confidence. Infrastructure would also need to be transitioned to a multi-region setup instead of solely multi-availability zone to ensure tolerance for region failures.
As an alternative we’d be much more comfortable with moving to a 12 hour force inclusion window. We think that this would be possible without significantly increased cost and staffing and improve what guarantees Arbitrum could offer today.
Addendum
It’s interesting to consider what other protocol options are possible to provide strong inclusion guarantees to Arbitrum users. This is an open area of research and I’ll list a few high level ideas here which are areas of future research and development.
- The first barrier to guaranteed inclusion in the happy path is soft confirmation by the sequencer. Currently this is a centralized mechanism, but sequencer decentralization mechanisms can provide stronger censorship guarantees to its mechanism
- The next barrier is ensuring that transactions with soft confirmation get posted onchain to achieve Ethereum finality. Modifications to the feed mechanism to include batch signatures from the sequencer could allow a broader set of entities to ensure that sequencer approved batches get posted.
Enhancing both of those mechanisms could potentially lead to much stronger inclusion guarantees without introducing additional reorg risk, and in fact greatly reducing the existing risk.