Our Proposal
We are proposing to analyse the impact of the three incentive programs run by the Arbitrum DAO and measure their impact on the eco-system and ROI. This will be achieved by analysing the pre and post-incentive performance of Grantees. Key areas that will be addressed are:
-
Analysing growth in the user base and cross-usage of protocols amongst users.
-
Analysing changes in user behaviour and frequency: Avg no of transactions per user, fee per user
-
Analysing the cost of acquiring users through CAC and the payback period.
-
Calculate the lifetime value (LTV) of users and LTV / CAC ratio.
-
Analysing the quality of users through retention cohorts and repeat ratios.
-
Build and analyse the behaviour of various Grantee segments (By scale, size and business category). Segments will be made by dividing Grantees into groups with similar characteristics or behaviours.
-
Benchmarking of ARB eco-system metrics with comparable L2s across metrics and protocol activity. This will enable us to outline areas where ARB is outperforming other L2s and where it is lacking.
Why our work is important
Capital efficiency is very important for achieving the best ROI. Incentive spend constitutes a significant portion of the foundation’s spend and allocating it for the right projects is most important for the long-term growth of the ecosystem. Our work will answer the following questions amongst several others:
- What is the ideal set of protocols for DAO to fund and support through Grants based on their Sector, Scale and traction? Understand if DAO should double down on established protocols or if DAO should make bets on newer projects. Or DAO should fund a DEX or a lending protocol etc.
- What is the optimal size of the grant to generate maximum impact?
- What is the ROI of various segments and who were the best-performing and worst-performing segments/grantees?
- For a sample set of sectors analyse why they underperformed or overperformed through analysis and discussions with Grantees/community members.
- Create a leaderboard of performers based on varied sets of metrics e.g. which segments created the most sticky users (best retention cohorts), which segments are driving Daily active user growth, and which segments drive maximum TVL.
- What sectors DAO should attract and fund more based upon the sector performance on Arbitrum vs sector performance on another ecosystem? Identifying market demand for certain protocols, mechanisms, and profit-driven actions
- What were the unique incentivization strategies implemented by the Protocols to attract new and recurring users? and what other protocols can be learned from it.
Methodology
We will segment Grantees based on different parameters and will conduct Pre and Post analysis of those segments for all 3 programs(STIP/ Backfund STIP and LTIPP).
Segments for Grantees
- Based on sectors
Protocols will be aggregated based on the services they offer.
Major categories will be
- Dexes
- Perps
- Lending / Borrowing
- Options
- CDPs
- Yield
- Based on the size of the Grant
- According to the predefined quantitative methodology, protocols will be divided into ‘High’, ‘Medium’ and ‘Low’ categories.
- The methodology for the categorization will be documented and presented separately.
- Based on the protocol Size/scale/recency (when was the protocol launched)
- According to the predefined quantitative methodology, protocols will be divided into ‘Large’, ‘Medium’ and ‘Small’ categories.
- The methodology for the categorization will be documented and presented separately.
Metrics for performance analysis for protocols and segments
- Cumulative users:
- Calculate the total users who have used the protocol and ARB since inception
- Monthly breakdown of new vs existing users showing how many new users were acquired in each week
- Daily and monthly active users:
- Daily Active Users (DAU)
- Monthly Active Users (MAU)
- Ratio of DAU / MAU
- Breakdown of DAU, MAU & DAU/MAU by new vs existing users:
- New to the respective protocol
- New to Arbitrium
- Existing users of Arbitrium.
- Breakdown of DAU, MAU & DAU/MAU by new vs existing users:
- Retention cohorts for each protocol and overall for the ARB ecosystem show retention at 1W, 2W, 4W, and 8W.
- Frequency: Analyse the Average number of transactions per week per user for Protocol and Arbitrium.
- Economics: Analyse trends in Average fee per transaction for protocol and overall Arbitrium.
- Analyse trends in user behaviour and activity by segmenting users based on :
-
Existing vs New wallets
-
Age of Wallet
-
Based on the ARB balance in the wallet
-
Did they hold ARB before the program
-
Nature/business of dapps interacted with e.g. Dexes.
-
Nature of activity mercenary miners, institutional investors, traders etc
(Segments for this section will be defined quantitatively and documented appropriately with the reasoning behind the decisions.)
- Analyse the overlap between the Protocols that received grants in STIP and LTIPP:
- Segment users by how many protocols they interacted with e.g. 1, 2, 3 etc
- Analyse the difference in the business performance of wallets which interacted with different numbers of Protocols (Retention, behaviour, metrics). E.g. Do wallets which interact with more than one Protocol have better retention compared to users who interacted with only 1 Protocol or do they have a higher average frequency of interactions with Arbitrium?
- Customer acquisition cost and LTV:
- LTV - Lifetime Term Value - The Gas contribution of a wallet is taken as the LTV provided by a wallet.
- Calculate the LTV of users at the overall Arbitrium level
- Calculate the customer acquisition cost (CAC)
- Analyse CAC vs LTV ratio
- Calculate the break-even LTV vs. CAC ratio for Arbitrium. At what level of activity and retention will ARB recover grant money in fees?
- Calculate payback period
- Analyse Unit economics :
- Avg Fees per Transaction
- Avg Fees per Wallet
- Avg No of transactions per user (Weekly and monthly)
- Analyse Gas contribution and payback period:
- Calculate the Gas fees generated by each Protocol pre and post-program.
- Calculate the incremental gas generated and payback period for the grant.
How we will present this information to the DAO
- A public Dashboard for the metrics we will analyze and a related document of methodologies and definitions.
- A report containing Insights and conclusions of our research and analysis.
Team Background
PYOR is a crypto data analytics company backed by Castle Island and Coinbase Ventures. We specialize in measuring the business performance of protocols/chains. We work with large institutional investors and protocols in the web3 space. We’ve worked with Ribbit Capital, M31 Capital, Tezos, Compound, ICP, Swell, QuickSwap, etc.
Past work
-
We work extensively with large institutional customers supporting their Crypto analytics and research needs. Our customers include Ribbit Capital and M31 Capital amongst others.
-
We extensively work with Protocols building custom solutions tailored to their needs. Some of the Protocols/chains we have worked with include Compound, Tezos, ICP, Swell, QuickSwap, and Osmosis among others.
-
We have built an interface X-ray for institutional investors to give them an in-depth look into the business and financial metrics. Our platform includes metrics around retention, LTV, user activity, stablecoin volumes etc.
The following contains a few examples of user activity analysis for Arbitrum that we’ve done previously -

Figure 1: Daily and Weekly active users

Figure 2: Monthly transactions count per user and Monthly Fees per user
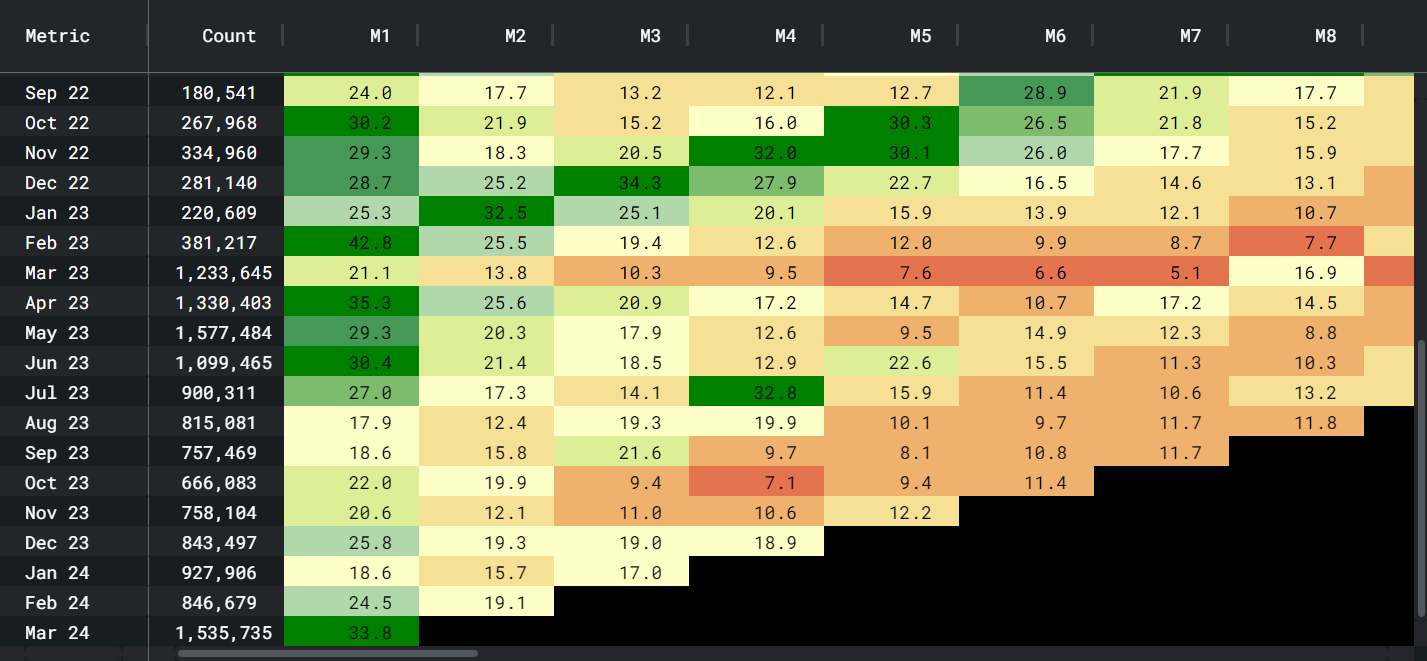
Figure 3: User retention cohort
- We regularly publish in-depth and quantitative reports and have partnered with the Ethereum Enterprise Foundation to publish research reports.
Requested Budget & Cost breakdown
- We request a budget of ARB 100k for this project.
- Budget breakdown:
| Cost | |
|---|---|
| On-chain data Data collection | 10,000 ARB |
| Infra cost for data modelling and analysis | 24,000 ARB |
| Team cost (3 Research analysts and 1 data scientist for 3 months) | 54,000 ARB |
| Engineering efforts for dashboard - Front end and back end | 12,000 ARB |